David B Dean
Machine Learning Researcher and Software Engineer
Audio-visual speech
Honours - Talking Face
I’ve been conducting research into various aspects of audio-visual speech since doing my Honours year in 2004, where I wrote a small C# application that could produce facial animations from transcriptions, and even recorded speech!
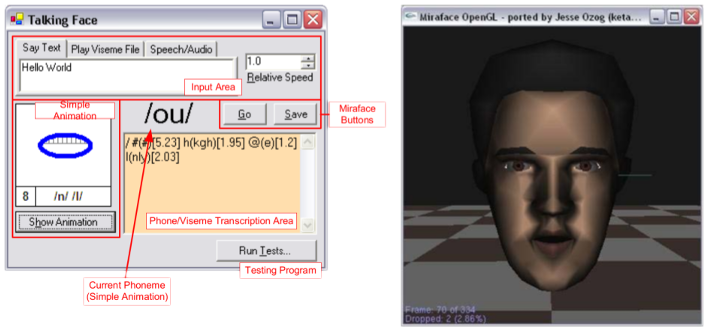
It wasn’t pretty, but it was interesting and won a couple of prizes at the Honours project expo that year.
PhD - audio-visual speech and speaker recognition
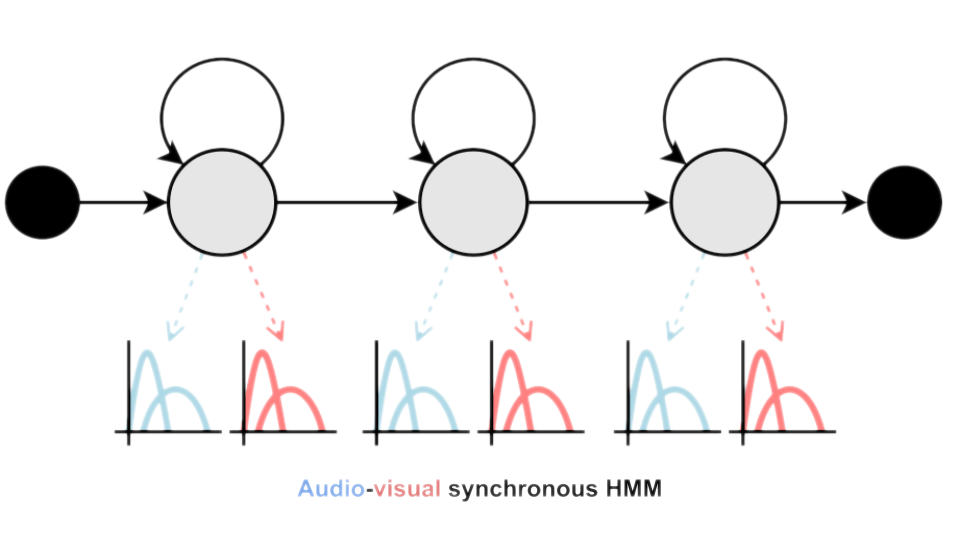
My PhD focused on, instead of producing visual speech, interpreting it, either for determining what audio-visual speakers were saying (Audio Visual Speech Recognition) or who the audio-visual speakers were. I made a number of interesting contributions during my PhD, but my main one was the development of a new Fused HMM Adaptation technique that allowed multi-stream audio-visual HMMs to be trained a little better than the state-of-the-art at the time, joint-training.
Post-doc - automotive AV speech recognition
I continued my audio-visual speech work into my post-doctoral research by collaborating with my student, Rajitha Navarathna, on improving the performance of audio visual speech recognition in noisy automotive environments, mostly focusing on the AVICAR database.

We found that the audio-visual SHMM approach can be extended with multiple audio and visual streams, with the more data available, the better the performance.
Post-doc - AV keyword spotting
More to come here…
Post-doc - Multimodal entity extraction
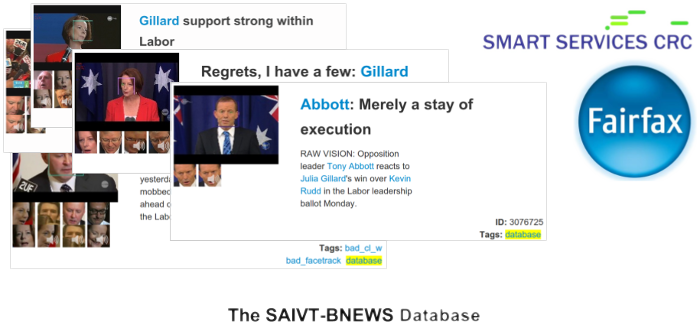
In collaboration with the Smart Services CRC and Fairfax Media, I collaborated with PhD students Houman Ghaemagghami and Kaneswaran Anantharajahto to produce an annotated dataset of short broadcast news segments for the purposes of evaluating a wide range of audio-visual research tasks, including speech detection, speaker diarisation, face recognition and diarisation, OCR and speech recognition. We have released the metadata for this database on github, along with scripts to download the original videos, and would love to see any new research on this database.
Post-doc - AV emotion recognition
More to come here…